
|
Welcome to my personal website.
I am Limin Fu, from Hunan, China. I have educational and professional backgrounds in multiple fields, and likes to work on challenging problems and develop interesting stuff. |

|
|
Current Work

|
Craftica is a creative sandbox game with ultra high degrees of freedom for building. It supports multiscale subvoxels so that smoother objects can be built in more realistic scales, and makes it possible to build very architectures. Craftica also provides a large number of electronic and mechanical as well as other related device items, allowing players to build sophisticated circuits and circuit-controlled electronic and mechanical devices. Players can even build vehicles, aircrafts, robots and computers etc. high-tech objects from items as basic as logical gates. Homepage: http://craftica.net |
Craftica was started as a small prototype to create a subvoxel-based virtual sandbox environment that could hopefully be useful for other projects. Though the result turned out quite positive, it took me a few months to finally decide to further develop this prototype into a actual game. The prototype was initially developed in the Dao programming language, it was then switched to use C++ for efficiency. This is my first time to develop a game, and so far I am still the sole developer for this game. To speedup development and compensate my poor skills in 2D graphic design and 3D modelling, I tried to solve most problems by programming. So, in addition to terrain generation, many things in the game (such as models, icons and placement rules etc. for the standard items) have been generated programmatically.
Craftica is now available on Steam as Early Access:
Some Other Work
| Dao | DaoStudio | DaoGraphics | CD-HIT | FLAME |
|---|---|---|---|---|
|
|
|

|
|
|
| Programming Language and Virtual Machine | Integrated Development Environment | Graphics Engine | High Performance Sequence Clustering | Fuzzy Clustering Algorithm |
当前工作
|
|
匠造奇境(Craftica) 是一款具有超高自由度的建造类沙盒游戏。它支持多尺度的亚体素,方便玩家以更真实的比例建造更平滑的物体和更优美的建筑。《匠造奇境》还提供了一系列电子和机械以及其他相关的设备器件物品,支持玩家在游戏里设计建造复杂的电路,以及由电路控制的电子与机械装置。玩家甚至可以从逻辑门等基本原件组装制造出诸如汽车、飞行器、机器人和电脑等高科技物品。 |
《匠造奇境》的最初原型来自于我的一个基于亚体素构建虚拟沙盒环境的小尝试。 尽管尝试的结果还不错,我也过了几个月才决定将原型进一步开发成一款游戏。 《匠造奇境》的原型最初是用道语言开发的,后来为了效率便改用C++开发。 这是我第一次开发游戏,而且到目前为止,这款游戏还是由我一个人开发。 由于我欠缺美工和3D建模方面的经验,同时也为了提高开发效率, 游戏除了地形完全由算法生成外,标准物品的模型和图标等也都通过编程由程序自动生成。 此游戏在2021年以前曾用《开物天工》作为中文名,后改为《匠造奇境》这个更方便记忆并有更好的识辨度的名字。
现在这款游戏可从Steam下载:
部分其他工作
| Dao | DaoStudio | DaoGraphics | CD-HIT | FLAME |
|---|---|---|---|---|
|
|
|
|
|
|
| 程序语言和虚拟机 | 集成开发环境 | 图形引擎 | 高性能序列聚类 | 模糊聚类算法 |
I am from the Hunan Province of China. I studied Mathematics at Fudan University (Shanghai) in 1996. Then I studied Physics in graduate school for about one year also in Fudan before going to ICTP (Trieste, Italy) to study in a multidisciplinary master program in 2001. Two years later, I went to the University of Turin (Italy) for my PhD study, and worked in a lab located in its cancer research center.
After PhD study, I worked for about one year and half at the ISI Foundation (Turin, Italy), then I moved to University of California, San Diego in 2009. Since 2015, I joined Research Center for High performance Computing as an associate professor at Shenzhen Institutes of Advanced Technology (SIAT). Then I left SIAT at the end of 2016 and founded a startup.
我来自中国湖南。 我本科就读于上海复旦大学数学系(96级)。 研究生期间在复旦读了一年物理硕士,然后去了在意大利Trieste的 ICTP(国际理论物理研究中心,下属联合国教科文组织) 参加一个跨学科的硕士课程(2001)。 两年后又去了意大利都灵大学读博士(2003), 并在下属都灵大学的肿瘤研究治疗中心做生物信息方面的研究。
2007年底博士毕业后我在都灵ISI Foundation做一年半研究。 之后于2009年去了加州大学圣地亚哥分校做博士后研究。 从2015开始,我作为副研究员加入到了中国科学院深圳先进技术研究院(SIAT)的 高性能计算技术研究中心。 2016年年底,我离开SIAT开始创业。
Software Projects:
Programming has been an integrated part of my work (and my hobby:)) since graduate school,
so over the years, I have created a number of open source projects.
Most of them are related to Dao, but in attempt to create various
modules and bindings for Dao, I managed to expand the projects to
touch various types of libraries and applications.
Current
Visual programming language, virtual robot and creative game. (Not yet ready to release).Dao - Programming Language and Virtual Machine
Dao is a lightweight and optionally typed programming language with many interesting features. It includes features that can make concurrent programming much simpler. It has well designed programming interfaces for easy embedding and extending.
- Optional typing with type inference and static type checking;
- Object-Oriented Programming (OOP) with classes and interfaces;
- Code section methods as a better alternative to functional methods;
- Native support for concurrent programming;
- Concurrent garbage collection;
- Support closures and anonymous functions;
- Designed and implemented as a register-based virtual machine;
- Portable implementation using standard C;
- Simple C programming interfaces for easy embedding and extending;
Size: about 68K lines of C codes.
Links:
daoscript.org,
github.com/daokoder/dao.
DaoJIT - Just-In-Time (JIT) Compiler Using LLVM
DaoJIT is a standard module for Dao to provide Just-In-Time (JIT) compiling. It is based on LLVM (llvm.org)
Size: about 3K lines of C++ codes.
Links:
daoscript.org,
github.com/daokoder/dao-modules.
ClangDao - Automatic Binding Tool Using Clang Frontend
ClangDao is a tool that can be used to automate the generation of Dao language bindings from the header files of C/C++ libraries. It uses the Clang (clang.org) frontend to parse header files. It has been used to generate bindings for over a dozen of libraries.
Size: about 8K lines of C++ codes.
Links:
daoscript.org,
github.com/daokoder/dao-tools.
DaoStudio - Integrated Development Environment for Dao
DaoStudio is an integrated development environment for Dao. It uses the Qt4 framework.
Size: about 11K lines of C++ codes.
Links:
daoscript.org,
github.com/daokoder/daostudio.
DaoGraphics - Dao Graphics Engine
DaoGraphics is a lightweight graphics engine written in C with interfaces to Dao.
- Support for both 2D and 3D graphics;
- Resolution independent 2D vector graphics;
- Support animation, particle system and terrain generation etc.;
- Support OpenGL 3.1+ and OpenGL ES3;
- Minimum dependency (Dao and GLFW3);
Size: about 22K lines of C codes.
Links:
daoscript.org,
github.com/daokoder/DaoGraphics.
DaoSQL - Module for Accessing SQL Databases
DaoSQL allows mapping Dao classes to SQL database tables, and provides a simpler way to access those tables through Dao class instances. Currently it supports PostgreSQL, MySQL (MariaDB) and SQLite3 backends.
Links: daoscript.org, github.com/daokoder/DaoSQL.
CD-HIT - DNA/Protein Sequence Clustering Program
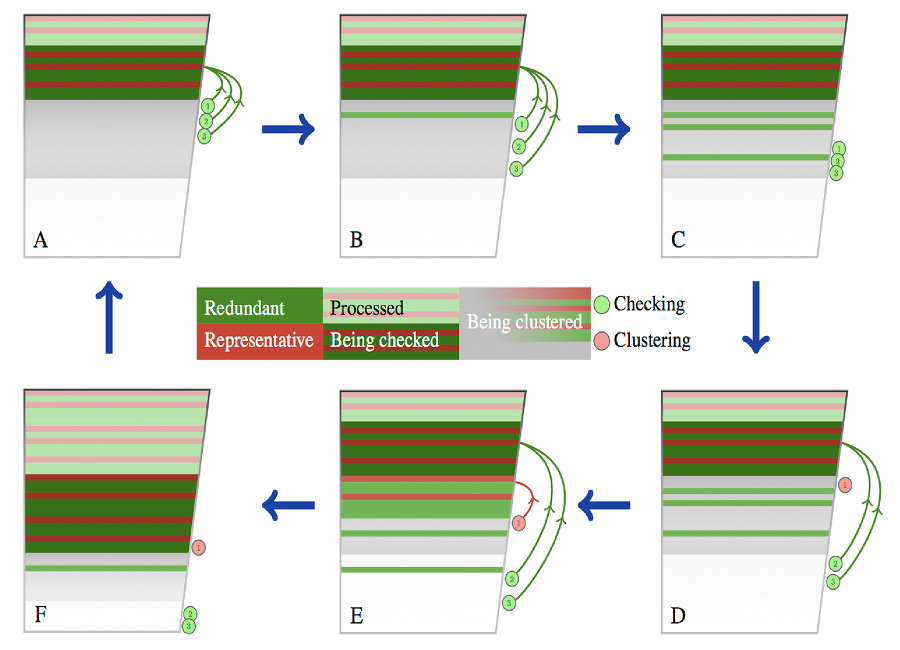
CD-HIT is a popular program for clustering DNA/protein sequences originally developed by Dr. Weizhong Li. It implements a greedy algorithm to cluster sequences incrementally and efficiently. I toke over the development in 2009 and rewrote most parts, in addition, I developed a novel parallelization technique that can speedup the clustering algorithm almost linearly on multi-core machines.
Links: cd-hit.org, cdhit.googlecode.com.
FLAME - Fuzzy clustering by Local Approximation of MEmberships
This FLAME is NOT the malware discovered in 2012:), it is a data clustering algorithm I developed some years ago. FLAME defines clusters in the dense parts of a dataset and perform cluster assignment solely based on the neighborhood relationships among objects.
Links: flame-clustering.googlecode.com.
GEDAS - Gene Expression Data Anlysis Studio
This is a software I developed along with the development of the FLAME algorithm. It provides user friendly interfaces for analyzing and visualizing gene expression data. Note: GEDAS is no longer maintained.
Size: about 15K lines of C++ codes.
Links:
sourceforge.net/projects/gedas.
软件项目:
从研究生阶段开始,我的学习和工作(以及主要爱好)就和编程密不可分。
因此,这些年来,我创建了不少开源项目。
其中最大的是Dao程序语言开发项目,其它项目也大都和Dao程序语言相关,
目标是建立一套Dao语言能使用的模块和工具。
这些项目的开发过程,使得我有机会涉猎不少不同的领域及相关的库和应用程序。
当前项目
可视化编程语言,虚拟机器人和创造性游戏。(暂不适合发布)Dao - 程序语言和虚拟机
道(Dao)语言是一个轻量级、支持可选类型标注的程序语言。它支持很多高级特性, 对基于多核的并行编程有很好的支持。它的C编程接口简单易用,方便嵌入或扩展。
主要特性:
- 支持可选类型标注,类型推导和静态检查;
- 支持基于类和接口的面向对象编程;
- 支持代码块方法(类似函数式方法);
- 支持闭包和匿名函数;
- 对并行编程有内置的原生支持;
- 有基于同步垃圾回收的内存管理;
- 设计和实现为基于寄存器的虚拟机;
- 使用跨平台的标准C实现;
- 有简单易用的C编程接口,方便嵌入或扩展;
- 有基于LLVM的及时编译器;
- 有基于Clang的自动封装工具;
代码规模: 约 6.8 万行C代码.
项目链接:
daoscript.org,
github.com/daokoder/dao.
DaoJIT - 基于LLVM的即时编译器
DaoJIT是一个给Dao提供及时编译的标准模块。 它基于LLVM (llvm.org)。
代码规模: 约 3 千行 C++ 代码.
项目链接:
daoscript.org,
github.com/daokoder/dao-modules.
ClangDao - 基于Clang前端的自动封装工具
ClangDao是一个可以从C/C++库的头文件自动(或半自动)地生成Dao语言的捆绑封装的工具。 它使用Clang(clang.org)前端的来解析C/C++头文件。 它已被用来生成十多个库的封装模块。
代码规模: 约 8 千行 C++ 代码.
项目链接:
daoscript.org,
github.com/daokoder/dao-tools.
DaoStudio - Dao语言的集成开发环境
DaoStudio是Dao语言的一个集成开发环境。 它基于服务器-客户端模式;带调试器; 编辑器和控制台内语法高亮;支持类VIM编辑模式。 使用Qt4框架开发。
代码规模: 约 1.1 万行 C++ 代码.
项目链接:
daoscript.org,
github.com/daokoder/daostudio.
DaoGraphics - 图形引擎
DaoGraphics是一个轻量级的图形引擎, 使用C语言开发,带Dao语言接口。
- 支持二维和三维图形;
- 支持任意分辨率二维矢量图形;
- 支持动画,粒子系统和地形生成等;
- 支持 OpenGL 3.1+ 和 OpenGL ES3;
- 最少的库依赖(Dao 和 GLFW3);
代码规模: 约 2.2 万行 C 代码.
项目链接:
daoscript.org,
github.com/daokoder/DaoGraphics.
DaoMake - 基于Dao的编译工具
DaoMake 是一个类似于CMake,但基于Dao的编译工具。 它的主要优点是:简单方便的语法;设计比较干净;可方便地根据编译平台和环境作定制; 能自动生成安装和卸载目标。
项目链接同Dao,以Dao的标准工具形式存在(dao/tools/daomake)。 代码规模约 4 千行行 C 代码。
DaoSQL - SQL数据库访问模块
DaoSQL是Dao的一个模块。它允许定义与SQL数据库表相对应的类,实现表纪录的数据域 与类成员域对应关系,并通过类实例实现对SQL表的方便访问。 Currently it supports 目前它支持 PostgreSQL, MySQL (MariaDB) 和 SQLite3 数据库.
CD-HIT - DNA和蛋白质序列聚类
CD-HIT 是一个比较流行的用于DNA和蛋白质序列聚类的程序。 此程序最初由李维忠博士开发,使用了贪婪优化算法实现了高效的增量聚类。 我从2009年开始对CD-HIT里的算法做改进,并重新设计实现了该程序的大部分。 这项工作中我开发了一个新的并行技巧,使得CD-HIT能在多核计算机上实现准线性的加速。
项目链接: cd-hit.org, cdhit.googlecode.com.
FLAME - Fuzzy clustering by Local Approximation of MEmberships
FLAME 是我读博时开发的一个新的数据聚类算法。 这个聚类算法的创新点在于通过构建数据点的邻近图,并在图上作类成员向量的 局部近似优化而算出数据点的最优模糊成员向量;通过这种方式,最终的聚类结果 能保留原始数据的局部拓扑结构。
GEDAS - Gene Expression Data Anlysis Studio
GEDAS 是我在开发FLAME算法的同时开发的一个用于基因表达数据的分析和可视化的软件。 该软件支持多个标准的聚类算法和一些基于基因语义学(Gene Ontology)的功能分析。 GEDAS已不再维护。
代码规模: 约 1.5 万行 C++ 代码.
项目链接:
sourceforge.net/projects/gedas.
Fields of Interest:
Machine learning, pattern recognition, combinatorial optimization, computer graphics, computer vision and their applications in bioinformatics (and any other exiciting fields).
Mostly as hobby, I am also interested in programming language design and implementation. Recently I also find robotics very interesting, maybe this will become another hobby of mine:).
Publications:
专业兴趣:
模式识别,机器学习,组合优化,计算机图形图像, 计算机视觉和相关技术在生物信息(或其它一些有意思的领域)里的应用。
作为爱好,我也对计算机程序语言的设计和实现很感兴趣。 现在我也对机器人学很感兴趣,可能会成为我的另一个主要爱好:)。
论文:
Educations
- 1996-2000, Fudan University (Shanghai), Mathematics (BS)
- 2000-2001, Fudan University (Shanghai), Physics
- 2001-2003, ICTP/SISSA (Trieste, Italy), Modeling and Simulation (MS)
- 2003-2007, University of Turin (Italy), Bioinformatics (PhD)
Experiences
-
Institute for Science Interchange (ISI), Turin, Italy
Junior Researcher, 2008-2009 -
University of California, San Diego, USA
Postdoctoral Associate, 2009-2013 -
Shenzhen Institutes of Advanced Technology (SIAT, CAS), Shenzhen
Associate Professor, 2015-2016
Preferred Tools
- Computer Desktop: Mac OS X;
- Programming Platform: Linux (Unix-like);
- Programming Languages: C, C++ and Dao;
- GUI/Application Framework: Qt;
- Version Control System: Fossil;
- Text/Code Editor: VIM;
- Image Editor: GIMP;
- Document Preparation System: LaTex;
Things I Like
- Paintings: my favourite paintings are from Van Gogh;
- SF Novels: my favourite is I, Robot from Isaac Asimov;
- Weiqi (Chinese Go): a perfect board game from ancient China;
- TV Series: The Big Bang Theory, Friends, Star Trek (TOS, and NG), Stargate (SG1);
教育
- 1996-2000, 复旦大学 (上海), 数学 (学士)
- 2000-2001, 复旦大学 (上海), 物理
- 2001-2003, ICTP/SISSA (意大利Trieste), 建模与模拟 (硕士)
- 2003-2007, 都灵大学 (意大利都灵), 生物信息 (博士)
经历
-
Institute for Science Interchange (ISI), 意大利都灵
Junior Researcher, 2008-2009 -
加州大学圣地亚哥分校
Postdoctoral Associate, 2009-2013 -
中国科学院深圳先进技术研究院
副研究员, 2015-2016
喜欢的工具
- 桌面系统: Mac OS X;
- 编程环境: Linux (Unix-like);
- 编程语言: C, C++ and Dao;
- 图形界面库: Qt;
- 版本控制: Fossil;
- 文本和代码编辑器: VIM;
- 图像编辑器: GIMP;
- 文档编写工具: LaTex;
喜欢的东西
- 绘画: 最喜欢梵高的画;
- 科幻小说: 最喜欢Isaac Asimov的I, Robot;
- 围棋:完美的棋类游戏;
- 电视剧: The Big Bang Theory, Friends, Star Trek (TOS, and NG), Stargate (SG1);